Einen Kubernetes-Cluster zu installieren und zu betreiben, lässt sich nur mit geeigneten Automatisierungen aufwandsarm umsetzen. Für die Installation von weiteren Komponenten und eigener Software ist diese ebenso notwendig. Der Ansatz im Application Management ist, Software so sehr zu abstrahieren, dass sie einfach funktioniert. Das wird beispielsweise mit Paketierungs-Komponenten wie helm erreicht.
Um dabei einen höheren Automatisierungsgrad zu erreichen, haben sich in den letzten Jahren verschiedene Konzepte im DevOps-Umfeld durchgesetzt. Continuous Integration & Delivery zählt dabei zu den bekanntesten.
Für Applikationen bietet MetaKube Accelerator genau diese Funktionalität. Der neue Fokus ist, schon während der Entwicklung dafür zu sorgen, dass Änderungen schnell und ohne Fehler durchgeführt werden können. Das erhöht den Grad der möglichen Individualisierung.
In diesem Beitrag beginnen wir mit dem Begriff, der die Grundlage des Produkts bildet: den Building Blocks. Bevor wir aber schauen, was sich dahinter verbirgt, gehen wir einmal durch den Aufbau von MetaKube Accelerator.
Zuallererst: Was ist MetaKube Accelerator?
MetaKube Accelerator (MKA) schließt programmatisch die Lücke zwischen der Softwareentwicklung und Kubernetes-Infrastrukturen. Mit Hilfe einer Open-Source-Toolchain werden wiederkehrende Tätigkeiten auf Basis einer CI/CD-Pipeline automatisiert. So lassen sich Softwarekomponenten, die für jedes Setup benötigt werden, einfacher bereitstellen und von Anfang an betriebssicher nutzen. MKA besteht im Wesentlichen aus drei verschiedenen Aspekten: Einer Software Supply Chain, Building Blocks und Control Repositories.
Die Software Supply Chain
Beim Software Supply Chain Management handelt es sich um das Herzstück von MKA. Es besteht aus einer CI/CD Pipeline, basierend auf GitLab und GitLab CI, mit standardisierten Aufgaben. Diese sind für beliebige Softwarekomponenten einsetzbar und übernehmen Aufgaben wie Image-Scans, Dateianalysen für YAML, JSON, etc. sowie die Prüfung mit Hilfe von generischen Testfällen.
Damit stellen wir sicher, dass die von der Supply Chain unterstützte Software bei jeder Änderung auf ihre Update- bzw. Lauffähigkeit als auch die Sicherheit überprüft wird. Darüber hinaus erstellen wir die optimale Standardkonfiguration und, falls nötig, Workarounds für die neue Version. Dabei ist uns wichtig, dass vor allem für automatisierte Deployments von Microservices immer die aktuellsten Versionen bereit stehen und von allen einfach und schnell ausgerollt werden können.
Jetzt aber Klartext: Was sind denn nun Building Blocks?
Während die Hauptaufgabe von MKA darin besteht, die Schritte zwischen Programmierung (Coding) und Installation (Deployments) so weit wie möglich zu automatisieren, ist das eigentliche Angebot das Ergebnis dessen: Die Building Blocks.
Building Blocks sind Helmfiles der verschiedenen Open-Source-Anbieter, die durch unsere Betriebserfahrungen erweitert und vorkonfiguriert sind. Jede Ressource der Building Blocks, die dabei referenziert wird, wird in der Software Supply Chain mitgeprüft. Schlussendlich werden die Helmfiles für verschiedene Nutzungsszenarien, wie beispielsweise das sequenzielle Installieren der Applikationen in mehreren Umgebungen, vorbereitet. Dabei ist es unerheblich, ob es sich um Monitoring, Ingresses oder Datenbank-Managementsysteme handelt.
Wir nutzen hierbei den Ansatz des Shifting-Left-Testing. Jedes Szenario, das während des Betriebs auftritt, optimieren wir mit geeigneten Tests oder empfohlenen Einstellungen schon im Vorfeld.
Mit anderen Worten: Wir übernehmen die Prüfung der Software Delivery, damit Ihr Euch ganz auf die Nutzung von Open-Source-Software und die Entwicklung Eurer eigenen konzentrieren könnt.
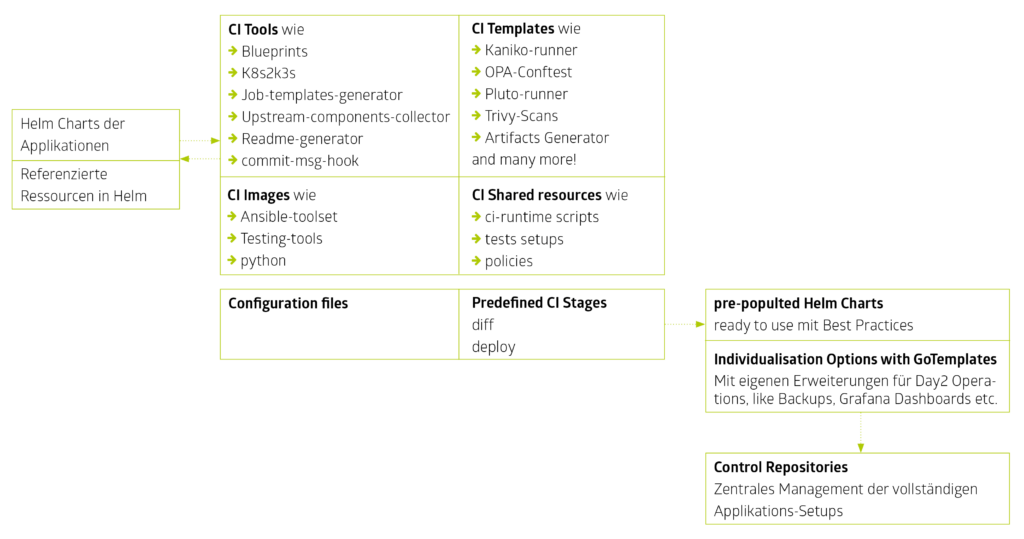
So können wir sicherstellen, dass DevOps- und Software-Engineers bequem ein zentrales Git Repository erzeugen, welches die Setup-Konfigurationen der MetaKube-Cluster beinhaltet.
Zentralisierung, Standardisierung, Individualisierung
Jeder Building Block besitzt eine eigene Sammlung an Testszenarien, die transparent und für jeden einsehbar sind. Außerdem können neue Tests über die bekannten Prinzipien von Git, also Merge- bzw. Pull-Request, auch von jedem Nutzenden erstellt werden. So werden neue Erfahrungen für jede Komponente programmatisch kommuniziert.
Mit Hilfe dieser Art von Supply Chain Management können wir die Qualität der Building Blocks sicherstellen. Dabei werden auch weitere Tests hinzugefügt oder für weitere Building Blocks optimiert.
Wenn also nun neue, systemweite Standards erkannt werden, wird es aus dem Aufgabenpool einzelner Komponenten herausgenommen und in der zentralen CI/CD-Pipeline für alle Building Blocks integriert. Das verringert den Pflegeaufwand, der für individualisierte Konfigurationen benötigt wird. Die Umsetzung geht auch ganz einfach: mit dem CLI-Tool mkactl könnt ihr in wenigen Schritten die Building Blocks auswählen, die ihr nutzen möchtet. Schaut auch gern auf unserer MKA Dokumentation vorbei! Im nächsten Beitrag schauen wir genauer in das Software Supply Chain Management von MetaKube Accelerator, denn dort werden die Building Blocks in ihrer Qualität erstellt.
Habt ihr Fragen oder Hinweise? Gerne können wir euch einmal alles live zeigen. Meldet euch einfach bei uns!






