Call all the things – die verschiedenen Service-Typen
Kommen wir zum ersten Thema mit Außenwirkung: Der Service Proxy. Endlich einmal eine Anwendung installieren. Die ganze Vorarbeit mit Lorbeeren schmücken. Doch wie erreichen wir das?
Wie im Beitrag Runtime bereits angesprochen, erzeugt Kubernetes ein Subnetz, in dem die interne Erreichbarkeit der Services gewährleistet wird. Eine externe Erreichbarkeit ist aber, abgesehen vom Kubernetes API Server, noch nicht vorhanden.
Kubernetes klassifiziert die Erreichbarkeit von Pods über den Typ eines Services:
- ExternalName,
- NodePort,
- LoadBalancer und
- ClusterIP.
Eine Übersicht könnte so aussehen:
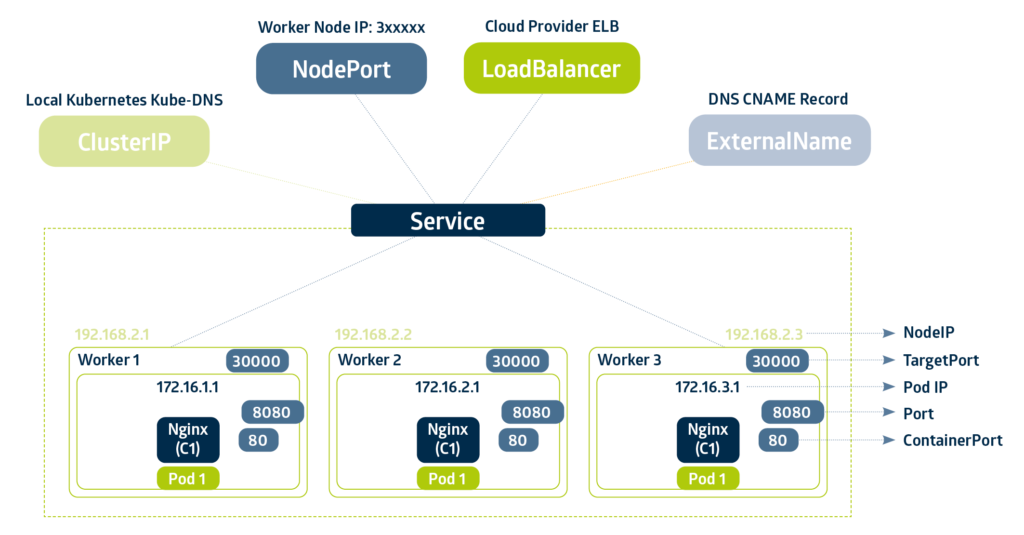
Der Service vom Typ External Name dient dazu, Kubernetes-interne Aufrufe auf externe Services weiterzuleiten. Das ist z. B. für Authentifizierungssysteme, die nicht auf Kubernetes gehostet werden sollen, sinnvoll.
Ein Service vom Typ ClusterIP ist der Standardeintrag für die Erreichbarkeit von Diensten innerhalb von Kubernetes. Sie besitzen einen Cluster-internen DNS-Eintrag der durch die Komponente “Coordination & Service Discovery” gemanagt wird.
Interessanter für uns sind aber die Typen NodePort und Load Balancer. Beide bieten die Möglichkeit, einen direkten Aufruf von außen auf die Anwendung möglich zu machen. Der Unterschied ist tatsächlich in der Vererbung zu finden: Ein Load Balancer-Service, ist ein erweiterter Service vom Type NodePort, und ein NodePort-Service ein erweiterter Service vom Typ ClusterIP. Während aber der NodePort sich weiterhin den Grundressourcen des Kubernetes Clusters bedient (die IP ist in dem Fall eine beliebige VM-IP einer Node von Kubernetes), kann ein Load Balancer-Service durch eine FloatingIP selbstständiger agieren. Dafür wird meist ein tatsächlicher Load Balancer eingesetzt.






