Ab einer bestimmten Nutzerzahl einer Software reicht ein Rechenzentrum nicht mehr aus: Entweder aufgrund der Erhöhung der Ausfallsicherheit oder dem Wunsch, die gleiche Qualität Deiner Applikation in anderen Ländern bereitzustellen. Das führt bei vielen Unternehmen zu der Entscheidung, ein georedundantes Setup zu entwickeln.
Um Dich bei der Planung zu unterstützen, betrachten wir in diesem Artikel drei Themenbereiche:
- Active/active und active/passive Setups
- Multi-regionale Cluster – Daten, Applikationen und Message Streaming
- Loadbalancing und DNS Management
Hot or Cold – Die Arten der Redundanz
Der entscheidende Faktor, wie Georedundanz eingesetzt werden soll, ist der gewünschte Zustand. Bei einer vollständigen Redundanz, also einem System, welches an zwei Standorten synchron die Workload erhalten und verarbeiten soll, muss jede Komponente redundant erarbeitet werden. Dabei spricht man von einer sogenannten Active-Active-Redundanz oder verteilter Redundanz.
Wenn für den Fall einer Störung das System an einem zweiten Standort genutzt werden soll, spricht man von einer “Active-Passive-Redundanz” bzw. Warm-Standby. Das ist die erste und wichtigste Entscheidung für den Aufbau von georedunanten Setups.
Wir gehen in diesem Beitrag von einer vollständigen Active-Active-Instanz aus. Das bedeutet, dass wir uns eine gleichmäßige Verteilung einer Webapplikation auf zwei Standorten genauer anschauen.
Zuerst: Daten, Daten, Daten
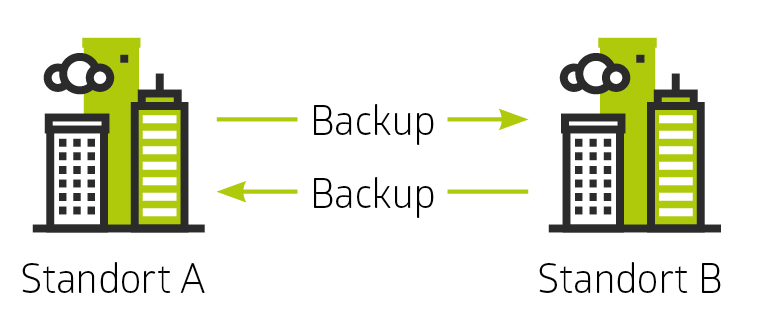
Bevor wir uns auf die Softwarekomponenten stürzen, betrachten wir einmal die Datenspeicherung. Dieser Layer bildet die Grundlage der Redundanz. Dabei handelt es sich in den meisten Fällen um ein Backup-Prinzip, wo eine Kopie der Daten in bestimmten Abständen in ein anderes Rechenzentrum transferiert wird. Beispielsweise wird dabei ein Datenbestand im Object Storage im Standort A gespeichert und zu einem späteren Zeitpunkt zum Standort B übertragen. (siehe Abbildung)
Cluster oder Message Streams?
Nachdem wir nun erfolgreich die Daten vervielfältigen, schauen wir uns nun einmal den Live-Betrieb an. Dabei muss die Redundanz der Applikationen für jede Komponente einzeln betrachtet werden. Das führt zu einer höheren Komplexität. Die Synchronisation zwischen zwei Datenbanken oder zwei Caching-Systemen ist dabei abhängig von der Geschwindigkeit, in der die Daten bereitstehen müssen. Wenn die nutzende Person auf einen beliebigen Standort zugreift, muss die Synchronisation zwischen den Standorten in wenigen Momenten erfolgen.
Wir nehmen für den Beitrag an, dass die Synchronisationszeiten vernachlässigbar bzw. im Rahmen des Möglichen liegt. Der letzte entscheidende Punkt ist die Machbarkeit mit Hilfe der bereits genutzten Software. Es gibt verschiedene multi-regionale Komponenten, die miteinander als Clusterverbund einsetzbar sind. Datenbanken haben beispielsweise schon integrierte Lösungen dafür. Selbstentwickelte Anwendungen wiederum sehen das nicht vor oder es besteht ein großer Aufwand in der Umsetzung.
Der schnellste Mehrwert lässt sich mit einem Message Streaming wie Kafka oder Pulsar realisieren. Tools für Message Streaming oder Queueing sind unabhängig von den Inhalten der jeweiligen Anwendungen und sind darauf spezialisiert, große Mengen an Daten zu verteilen.
Safety First
Die überregionale Kommunikation benötigt zudem einen sicheren Datenverkehr, sodass der vorher interne Traffic geschützt werden muss. Eine TLS-Verschlüsselung und Authentifizierung bzw. die Einrichtung eines VPN zwischen den zwei Standorten stellt dabei das Minimum dar.
Da bietet es sich an, auch einmal darüber nachzudenken, was noch weiter abzusichern ist. Sei es durch eine interne Rollenstruktur pro Applikation, Clusterinterne TLS-Verschlüsselung, oder mit Hilfe von Sicherheitsrichtlinien für deine Pods. Mit jedem weiteren Tool und jedem neuen Standort kommen neue Angriffsvektoren dazu. Da das Thema sehr vielfältig ist, betrachten wir diese Punkte in einem Folgeartikel.
Ready for Failover!
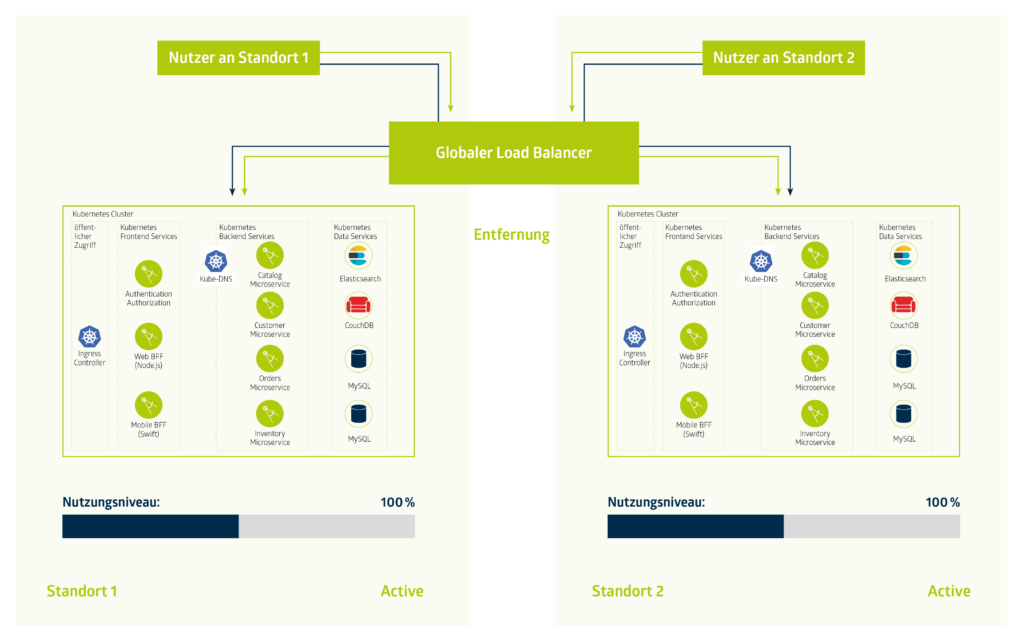
Jetzt haben wir Daten gespiegelt und Applikationen über Standorte hinweg miteinander verbunden. Jetzt fehlt nur noch ein Element – Der Load Balancer.
Betrachtet man den Load Balancer allein, wiederholen sich die Überlegungen wie bei der Daten- und Applikationsredundanz. Hier kommt noch ein wichtiger Bestandteil dazu: Zu welchem Standort die nutzende Person geleitet werden soll, ist ausschlaggebend für die Konfiguration.
Dafür bieten sich zwei Szenarien an:
- Separate Subdomains für jeden Standort
- Ortsabhängiges Routing
Beim ersten Szenario sind eure Systeme logisch voneinander getrennt. Somit wählt Ihr anhand Eurer Anwendungslogik einen der Standorte. Dabei ist jeder Load Balancer pro Standort eigenständig zu betreiben. Besser wäre natürlich das Routing innerhalb eines Load-Balancer-Clusters über beide Standorte auf die selbe Domain zu münzen. Dafür lohnt es sich einen Blick auf einen Anycast Router zu werfen. Der ermöglicht es, mehrere Endpunkte auf eine einzelne IP zu terminieren und den Router die Arbeit erledigen zu lassen. In beiden Fällen sind Health-Checks der Instanzen unerlässlich.
Der Aufbau eines georedundanten Setups ist eine Herausforderung für jedes Projekt und jedes Unternehmen. Um Dir den Start so einfach wie möglich zu machen, haben wir mit dem Start unserer dritten Region in Frankfurt eine weitere Möglichkeit der Redundanz und Absicherung zur Verfügung gestellt. Wenn Du Unterstützung für ein HA-Setup brauchst, freuen wir uns natürlich Dir dabei zu helfen!






