Es ist kein Geheimnis, dass Kubernetes sich zu einem der beliebtesten Tools für Container-Orchestrierung entwickelt hat. Gleichzeitig können die zahlreichen stattfindenden Prozesse in Kubernetes eine Herausforderung sein. Daraus resultiert die Frage, wie behält man den Überblick über all die laufenden Prozesse und kann gleichzeitig eine optimale Performance gewährleisten? Genau dafür ist Kubernetes Monitoring unerlässlich, denn es werden kontinuierlich Daten über die Leistung eines Systems gesammelt, gespeichert und analysiert.
Monitoring als Blackbox?
Ein Problem lässt sich nur dann lösen, wenn man sich dessen bewusst ist. Daher ist es wichtig, präzise zu ermitteln, welcher Dienst tatsächlich betroffen ist. Auch wenn Kubernetes nicht unbedingt als Blackbox gilt, kann es in einem komplexen und verteilten System dennoch schwierig sein, die genaue Ursache eines Problems zu identifizieren. Verwaltungsteams verlieren in solchen Situationen oft den Überblick. Daher ist ein robustes Monitoring-Tool unerlässlich
Im Kontext von Kubernetes haben sich erwartungsgemäß viele Open-Source-Tools entwickelt, die verschiedene Aspekte des Monitorings abdecken. Diese Tools überwachen Log-Daten, bieten Tracing-Funktionen an und wenden Metriken auf die Service-Prozesse an. Damit kann die Leistung der gesamten Anwendung sowie ihrer einzelnen Komponenten nachverfolgt werden.
Observability vs. Monitoring
Monitoring und Observability sind zwei Konzepte, die oft miteinander verwechselt werden. Kurz gesagt, Monitoring sagt dir, ob Dein System funktioniert oder nicht, während Observability erklärt, warum es nicht funktioniert.
Monitoring ist proaktiv: Du definierst Metriken und Alarme, die Dir sagen, wann Dein System nicht so funktioniert, wie es sollte. Observability hingegen ist eher reaktiv: Es gibt Dir Einblicke in die internen Zustände Deines Systems, basierend auf den externen Ausgaben. Tools wie Prometheus liefern Monitoring-Daten, während Jaeger und ELK Stack dir dabei helfen, die Observability zu verbessern.
Kubernetes Monitoring ist also nicht nur eine Frage des „Ob“, sondern des „Wie“. Mit den richtigen Tools und Praktiken kannst Du sicherstellen, dass Deine Container und Anwendungen nicht nur laufen, sondern auch performant und fehlerfrei sind. Behalte Deine Container im Blick und sorge so für ein optimales Nutzererlebnis.
Best Practices für Kubernetes Logging und Monitoring
- Sammle alle Logs: Logs bieten einen Einblick in das Verhalten Deiner Anwendung und können bei der Fehlerbehebung hilfreich sein. Es ist daher wichtig, alle Arten von Logs zu sammeln – Systemlogs, Anwendungslogs und Ereignislogs.
- Nutze Monitoring-Tools: Kubernetes alleine bietet keine eingebaute umfassende Monitoring-Lösung. Glücklicherweise gibt es Tools wie Prometheus, Grafana und Mimir, die speziell für das Monitoring in Kubernetes entwickelt wurden. Sie können helfen, Leistungseinbrüche zu erkennen und zu analysieren.
- Automatisiere das Monitoring: Kontinuierliches Monitoring kann ein zeitaufwendiger Prozess sein. Automatisiere daher, wo immer es möglich ist, um sicherzustellen, dass Du keine wichtigen Daten verpasst.
- Erstelle Dashboards: Dashboards ermöglichen es, wichtige Daten auf einen Blick zu sehen. Sie sollten so konzipiert sein, dass sie die wichtigsten Metriken hervorheben und den Status des Systems schnell und effizient kommunizieren können.
Prometheus Monitoring: Vor- und Nachteile
Prometheus hat sich weitgehend als Standard-Tool für das Monitoring in Kubernetes etabliert. Ursprünglich als Projekt der Cloud Native Computing Foundation (CNCF) entstanden, wurde Prometheus von Grund auf für Kubernetes als Open Source Software (OSS) entwickelt.
Prometheus kann Daten aus allen Ebenen der Kubernetes-Architektur sammeln. Sein zugrundeliegendes Datenmodell ermöglicht die Auswertung verschiedener Dimensionen durch eine eigene Abfragesprache namens PromQL. Ein eingebauter Alarmmechanismus warnt, wenn die tatsächlichen Daten von den erwarteten Werten abweichen. Darüber hinaus ist Prometheus relativ einfach zu bedienen, was zur stetig wachsenden Nutzerzahl beiträgt.
Trotzdem weist Prometheus einige Schwächen auf. Eines der Probleme betrifft die Skalierbarkeit. Während das Tool gut für einzelne Cluster oder begrenzte Umgebungen geeignet ist, kann es größere Systeme oft nicht effektiv handhaben. Zusätzlich speichert die Software Metriken im Dateisystem, was die Langzeitlagerung ineffizient gestaltet.
IT-Dienstleister kritisieren zudem die fehlende Mandantenfähigkeit, da sie ein System benötigen, auf das sowohl sie als auch ihre Kunden zugreifen können. Ebenso ist es mit Prometheus nicht trivial, Daten aus verschiedenen Clustern zu aggregieren. Daher kann man mit Prometheus allein keinen zentralen Alarmmechanismus einrichten.
Trotz dieser Einschränkungen bringt Prometheus eine Reihe von Vorteilen mit sich, die es zu einem bevorzugten Tool in der Kubernetes-Welt machen:
- Integration mit Kubernetes: Die enge und nahtlose Integration mit Kubernetes ermöglicht einen umfassenden Einblick in die Leistung der Anwendungen.
- Flexibilität durch PromQL: Die Prometheus Query Language (PromQL) ermöglicht das Durchführen von komplexen Abfragen und Analysen, was eine detaillierte Leistungsüberwachung ermöglicht.
- Eingebauter Alarmmechanismus: Das eingebaute Alarmierungssystem von Prometheus ermöglicht es Teams, auf Probleme schnell zu reagieren und Ausfallzeiten zu minimieren.
- Leichte Benutzerfreundlichkeit: Prometheus ist einfach einzurichten und zu bedienen, was es zu einer guten Wahl für Teams macht, die neu in der Überwachung sind oder eine schnell umsetzbare Lösung suchen.
- Aktive Community und Unterstützung: Als Open-Source-Projekt verfügt Prometheus über eine aktive Community und umfangreiche Dokumentation, was eine zusätzliche Unterstützung bietet.
Effektive Monitoring Dashboards
Eine praktikable Lösung, um die genannten Einschränkungen von Prometheus zu umgehen, ist die Kombination mit einem Monitoring-Tool, das verbesserte Skalierbarkeit, dauerhafte Speicherung und Mandantenfähigkeit bietet. Prometheus ist für die Sammlung der leistungsrelevanten Metrikdaten der Services, Pods und Nodes zuständig und übergibt sie auf der Cluster-Ebene an das Monitoring-Tool Mimir, das aus dem Projekt Cortexmetrics hervorgegangen ist. Auch Cortex ist ein Projekt der CNCF.
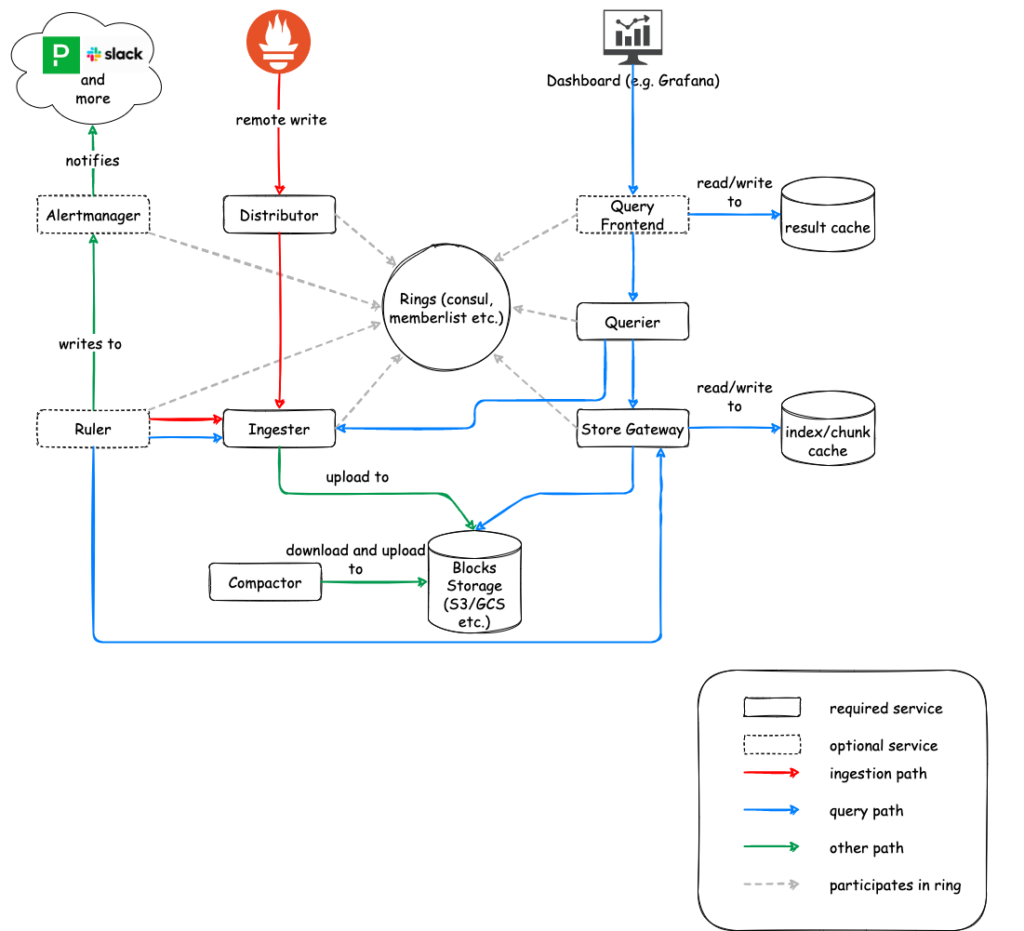
Mimir wurde von Grafana Labs entwickelt, dem Unternehmen hinter dem weit verbreiteten Visualisierungstool Grafana. Das Grafana-Frontend kann die umfangreichen Metriken aus Mimir effektiv in Monitoring-Dashboards darstellen. Diese können dann über eine CI/CD-Pipeline (Continuous Integration/Continuous Deployment), wie zum Beispiel Gitlab CI/CD, bereitgestellt werden. Grafana ist bekannt für seine Robustheit, einfache Installation, vielfältige Filteroptionen und eine zentrale Alarmfunktion. Es kann auch mit vielen externen Datenquellen integriert werden und verwendet dabei jeweils die spezifischen Abfragesprachen dieser Datenquellen. Mimir und Grafana erleichtern so die Zusammenarbeit über Organisationsgrenzen hinweg.
Open-Source-Tool für Log-Aggregation
Weder Prometheus noch Mimir können jedoch mit Logdateien umgehen. Daher ist die Kombination mit einem Log-Aggregator sinnvoll, um alle Anforderungen an ein Monitoring-System zu erfüllen. Eine passende Wahl wäre Loki, das ebenfalls aus dem Grafana-Umfeld stammt. Während Mimir die Kubernetes-Systeme hauptsächlich auf Basis von harten Metriken überprüft, sammelt Loki die Log-Informationen und speichert sie online.
Aus Compliance-Gründen ist es ratsam, Logdateien und Metriken getrennt zu halten. Logdateien enthalten wichtige Informationen wie zum Beispiel, wer wann und von welcher IP-Adresse auf eine Anwendung zugegriffen hat. Es ist sinnvoll, diese Protokolle für eine eventuelle spätere Nutzung zu speichern, da die Ursache eines Problems manchmal in diesen Informationen verborgen sein kann. Daher ist Loki eine wertvolle Ergänzung zu Mimir.
Erleichterung der Arbeitslast mit Kubernetes Monitoring
Die Monitoring-Tools erleichtern die Arbeit der Administrator:innen spürbar. Teams werden zeitnah informiert, wenn Prozesse nicht wie vorgesehen verlaufen, und die Suche nach der Ursache ist in der Regel unkompliziert. Dafür sind lediglich zwei Bedingungen erforderlich: Das Administratoren-Team muss die Schwellenwerte festlegen und die Anwendung sollte in der Lage sein, die entsprechenden Metriken bereitzustellen. Bei modernen Cloud-Anwendungen ist dies in der Regel bereits gegeben, bei älteren Anwendungen könnte etwas Entwicklungsarbeit erforderlich sein.
Möchtest Du auch wissen, wie das in der Praxis aussieht, dann melde Dich zu unserem nächsten Deep Dive Workshop zum Thema Observability, Monitoring & Alerting an.






