In unserem ersten Beitrag der Blogreihe “Managed Kubernetes 101: Der Einstieg” haben wir aufgezeigt, was Kubernetes eigentlich ist. Nun ist es an der Zeit, einmal aufzuzeigen, welche Basis-Komponenten es benötigt. Dieser Artikel erklärt Euch die Komponenten aus dem CNCF-Layer “Runtime”, die die Grundlage für das bekannte Container-Orchestrierungs-Tool bilden.
Put it all together!
Es existieren viele verschiedene Basiskomponenten auf der Ebene “Runtime”. Ein mögliches Zielbild könnte so aussehen:
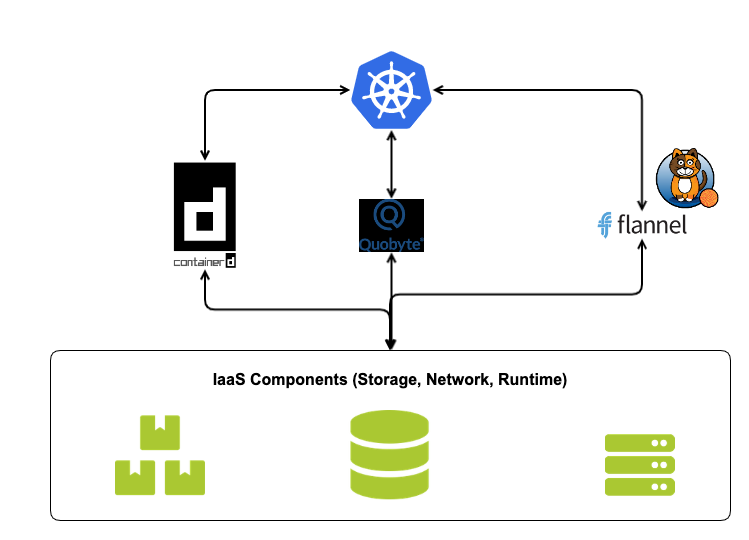
Die drei Komponenten sind stellvertretend mit containerd als Container Runtime, Quobyte als Cloud Storage und Canal als Cloud Network präsentiert.
Schauen wir uns diese drei Ebenen einmal genauer an.
Container-Runtime und -Verwaltung: Alles läuft getrennt zusammen
Wie funktioniert also die Verwaltung von Containern? Kubernetes hat sich für verschiedene Lösungen geöffnet, die eine standardisierte Schnittstelle namens Container Runtime Interface (CRI) verwenden. Die Container Runtime läuft getrennt von der eigentlichen Containerverwaltung und bietet über diese Schnittstelle eine externe Steuerung. Da diese Schnittstelle auch gewartet werden muss, ist dies die erste Komponente, die in das Kubernetes-Lifecycle-Management integriert ist. Der bekannteste Vertreter ist Containerd, das ursprünglich mit Docker verwoben war und später eigenständig wurde.
Seit der Einführung von Kubernetes wurden jedoch auch andere Container-Laufzeiten eingeführt. CoreOS versuchte sich mit rkt zu etablieren, RedHat übernahm CoreOS und nennt es jetzt podman und andere wiederum versuchen sich an lxd.
Damit die Runtime von Kubernetes genutzt werden kann, benötigt man ein CRI. Das Zwischenspiel auf Interface-Ebene ermöglicht eine präzise Steuerung, kann auf der anderen Seite aber zu einem großen Aufwand in der Einarbeitung und Auswahl führen. Es ist aber nur eine von mehreren Kommunikationsschichten, die viel Aufmerksamkeit erfordert.
Es wird also schon sehr komplex bei der Wahl und dem Betrieb einer geeigneten Container-Runtime für Kubernetes.
Containerd ist die am weitesten verbreitete Lösung. Sie ist Cloud-tauglich, betriebssicher und seit über drei Jahren mit einem offiziellen Release 1.0.0 auf dem Markt.
Be persistent in an ephemeral world
Die größte Veränderung in einem containerisierten Umfeld ist die Volatilität der Anwendungen. Um den zusätzlichen Aufwand von Datenpersistenz in diesem Umfeld zu umgehen, ist meist der Ansatz von “Ephemeral Apps” der passendste. Dabei werden Daten nicht zusammen mit den Applikationen gespeichert, sondern auf zentrale Umgebungen ausgelagert.Die Liste an Entscheidungen wird also auch hier größer: Ein Load Balancer, der alle Verbindungen neu aufbaut? Alles klar. Ein Datenbank-Managementsystem, die eine existierende Datenbank jedes mal neu einliest? Moment Mal!
Natürlich ist das eine grobe Verallgemeinerung, aber es ist normalerweise die erste Änderung in mancher Software-Logik, den man meist nicht erwartet.
Aber wie dem auch sei (wir erklären das Thema gerne in einem anderen Blog), Kubernetes bietet auch die Möglichkeit, seine Daten länger zu speichern, als ein Container lebt. Ähnlich wie bei der Container Runtime sprechen wir zunächst von CSI – einem Container Storage Interface. Diese Schnittstelle wird ebenfalls von verschiedenen Anbietern bereitgestellt. Kubernetes wird mit einer Standard-CSI geliefert, für den Fall, dass jemand die Idee haben möchte, lokale Pfade an einen Knoten anzubinden – in einer Welt des Wandels, in der jeder Knoten einen anderen ersetzen kann, nicht die „Best Practice“-Lösung. Dennoch ist es durchaus machbar.
Die Entscheidung nach einem guten CSI ist in der Fülle nicht leicht: rook-ceph als bereits etabliertes verteiltes Speicherwerkzeug, StorageOS für schnelle Read-IOPS?
Da die Speicherverwaltung eines der sensibelsten Themen in der IT ist, sind auch die Softwarelösungen komplex aufgebaut und bieten verschiedene Features, die jedoch in der Standardinstallation womöglich deaktiviert sind, um die Sensibilität deutlich zu machen. Dies wiederum bedeutet, dass viel Zeit für die Einarbeitung und Konfiguration aufgewendet werden muss und einige Mitarbeiter bestenfalls bereits Erfahrung im Storage-Management haben müssen.
Social Networking – the technical way
Nun könnte man mit wenigen Befehlen bereits mit Hilfe eines Installationsprogramms, wie kubeadm oder kubespray, Kubernetes installieren. Aber schauen wir uns erst einmal an, welche Drittsoftware nach der Installation gestartet wird.
Da eines der Grundprinzipien der Containerisierung darin besteht, einen Prozess pro Container zu starten, werden zwangsläufig mehr als nur einige wenige Container benötigt. Im VM-Kontext könnte man mit solch einer Anzahl schnell auf verschiedene Engpässe stoßen, von denen einer auch die Containerisierung betrifft: die Allokation. Jedem Container wird eine IP zugewiesen, und es wäre für jedes Netzwerk eine echte Herausforderung, die Flut von IPs und vor allem die regelmäßige Neuzuweisung zu bewältigen.
Um diesen Engpass zu vermeiden, wendet Kubernetes das Prinzip der internen IP-Zuweisung an und umgeht damit die Veröffentlichung einer jeden Komponente im restlichen Netzwerk. Mit einem geeigneten Werkzeug wird ein dediziertes Subnetz erzeugt. Dieses Netz wird durch ein geeignetes Netzwerkmanagement-Tool erstellt und verwaltet. IPTables und IP-in-IP-Prinzipien werden verwendet, um das Routing zwischen den einzelnen Kubernetes-Knoten sicherzustellen. Für simples Routing kann man die Komponente flannel verwenden. Für eine erweiterte Netzwerkeinstellung innerhalb des Kubernetes-Subnetzes ist Calico eine geeignete Wahl.
flannel + calico = Canal
Der Hauptunterschied zwischen flannel und Calico ergibt sich dabei im benutzten Netzwerk-Layer, im Prinzip der Data Encapsulation und des damit einhergehenden Routings. Besonders im Hinblick auf Performance wird für eine bessere Trennung zwischen Netzwerk und Policies das Kollaborationsprojekt Canal (Calico + Flannel = Canal) empfohlen, bei dem das Netzwerk Overlay flannel und die Policy-Komponenten von Calico genutzt werden.
Allein die Planung des passenden Netzwerksegments für das Subnetz kann schnell zu Fehlern führen. Manchmal können sogar das Cloud-Betriebssystem und die integrierte Überwachung der erzeugten VMs Probleme verursachen.
Der größte Aufwand ist jedoch in den Netzwerkrichtlinien zu sehen. Wie bei jeder guten Konfiguration ist auch hier ein sehr großer Aufwand zu leisten. Dabei helfen nur viele Best Practices und Netzwerkadministratoren mit Erfahrung.
Damit haben wir alles für den Layer “Runtime” abgedeckt. Der nächste Blogbeitrag beschreibt die Schicht “Orchestration & Management”. Dort schauen wir uns einmal die zentralen Komponenten eines Kubernetes Clusters näher an.
Habt ihr Fragen oder Hinweise? Meldet euch einfach bei uns – wir freuen uns über jeden Kubernetes-Enthusiasten.






